其实题目不太准确,这篇短文介绍的是二项分布线性模型, 也就是当响应变量为01时的线性模型,例如物种是否出现,病人是否需要住院,学生是否成功考入大学,英语四六级成绩是否及格等。逻辑斯蒂回归模型,是二项分布线性模型中的一种,也是最广泛的一种。
事情还要从1935年说起。那一年,英国伦敦大学学院的C.I. Bliss 在《Annals of Applied Biology》上发表论文The Calculation of the Dosage**-**Mortality Curve。这篇论文的表4,就是现在广泛用于逻辑斯蒂回归教学的beetle数据。该数据是C.I. Bliss从Strand在1930年发表的论文中摘出来的。
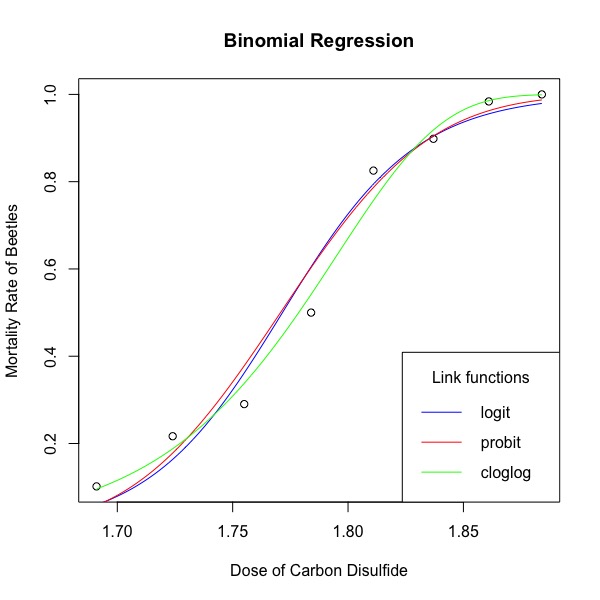
Bliss的这篇论文主要以杂拟谷盗**(Tribolium confusum)**为例,系统介绍拟合存活比例曲线的方法。杂拟谷盗是一种粮食害虫。当时生物学家将481只杂拟谷盗分成8组,每一组分别在暴露在不同浓度的二硫化碳5小时,之后记录每个组有多少只甲虫死了。由于甲虫对二硫化碳的反应只有两种可能,要么存活,要么死亡,所以这个数据集是典型的二项分布数据。
在这篇论文中,Bliss提出了一种连接函数,也就是事件发生与否,用转换以后的正态分布累计曲线去估算,称为Probit。实际上,二项分布线性模型的连接函数有三种,分别为logit, probit以及cloglog。 logit、probit以及cloglog都是统计变换,目的是将二项分布数据转换为一种形式,以便能用线性模型估计直接估计模型的参数。其中最常见的为logit,使用logit连接函数的二项分布回归称为逻辑斯蒂回归。logit是事件发生与是否发生的比例 (odds)的对数值,形为log**(y/(1-y)),称为log odds。cloglog是complementary log log的缩写,是将响应变量进行两次log变换, 公式为log(-log(1-y))**。 cloglog常用来拟合数据出现大量极端数值的数据, 例如,大样地的幼苗的负密度制约研究中,部分胸径等级的树苗只有很少一部分死亡,用cloglog能较准确捕捉到与树苗死亡相关性较强的环境因子, 如同种密度制约、光环境等。
下面用R代码演示如何进行二项分布回归,分别用logit, probit以及cloglog三种连接函数。
1 | library(broom) |
1 | \#####第二种方法,每个个体生存状态的长数据格式。glm是可以接受这种格式的。 |