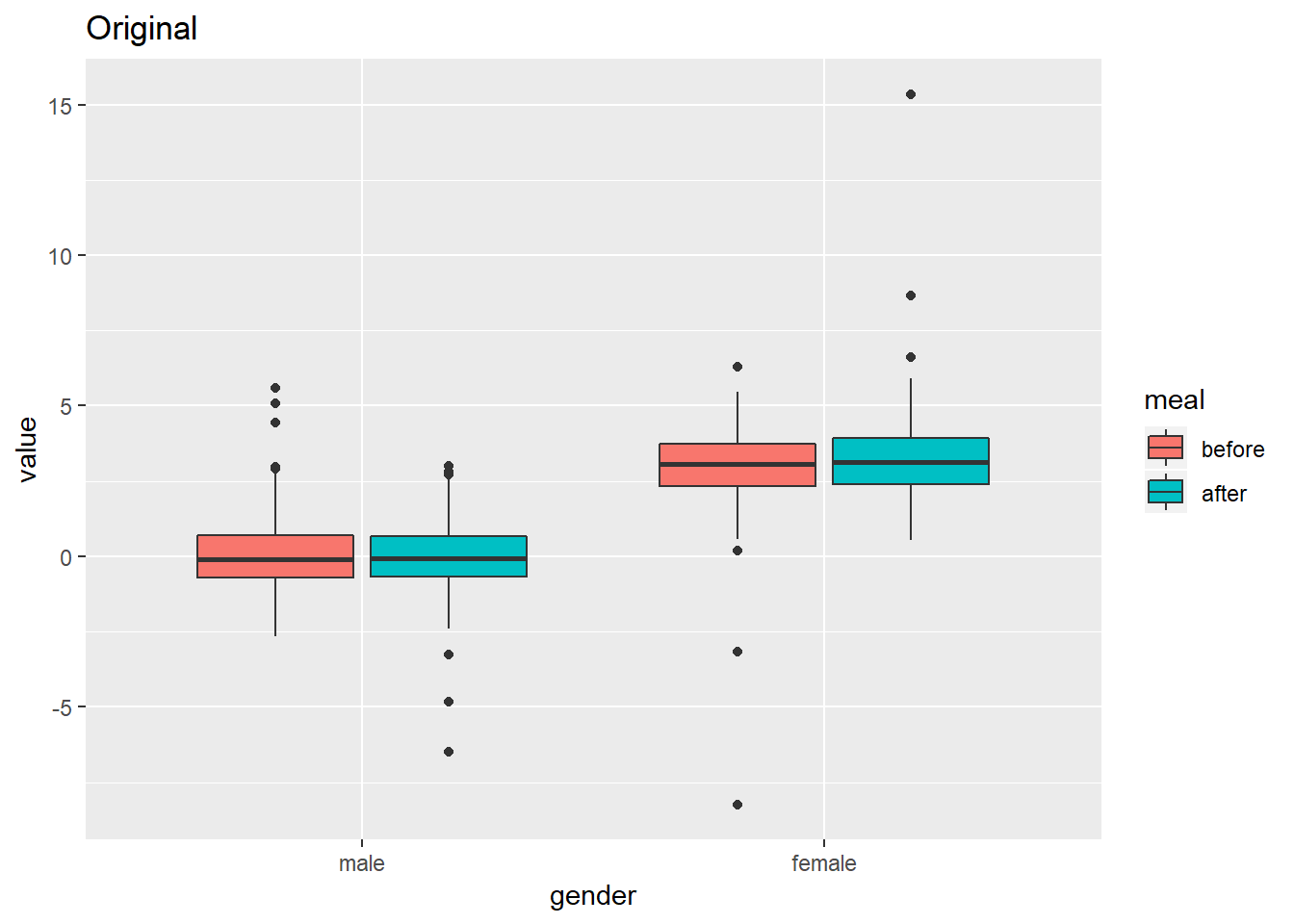
假设500人中有男女若干,现要比较饭前(before)和饭后(after)某生理指标的变化。由于数据誊写错误,测量指标中出现了一些异常值(outlier)。 问,如果按照性别以及饭前饭后分组,怎样去掉各组内的异常值?
思路:先定义识别和转换异常值的函数, 将一个向量中的异常值转换为NA。再用dplyr程序包将该函数应用于各组数据。
解答:
1 | library(ggplot2) |
1 | test_dat2 <- test_dat %>% |
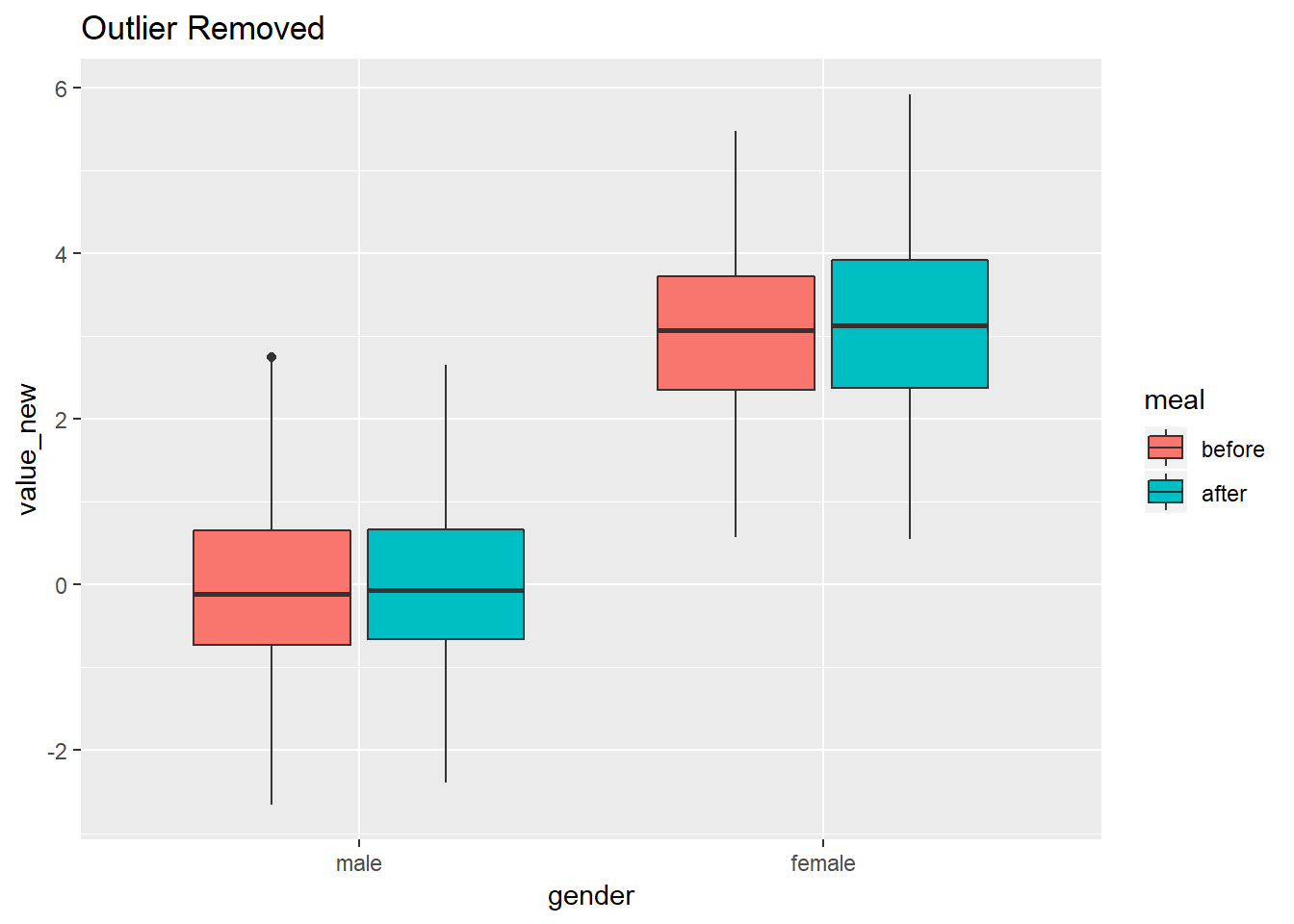
假设500人中有男女若干,现要比较饭前(before)和饭后(after)某生理指标的变化。由于数据誊写错误,测量指标中出现了一些异常值(outlier)。 问,如果按照性别以及饭前饭后分组,怎样去掉各组内的异常值?
思路:先定义识别和转换异常值的函数, 将一个向量中的异常值转换为NA。再用dplyr程序包将该函数应用于各组数据。
解答:
1 | library(ggplot2) |
1 | test_dat2 <- test_dat %>% |